A ring buffer is also known as a queue or circular buffer and is a common form of queue. This is a popular, easily implemented standard, and although it is presented as a circle, it is linear in the base code. A ring queue exists as an array of fixed length with two pointers: one represents the beginning of the queue, and the other represents the tail. The disadvantage of this method is its fixed size. For queues where items should be added and removed in the middle, and not just at the beginning and end of the buffer, implementing a linked list is the preferred approach.
Theory of the buffer
It is easier for the user to make the choice of an effective array structure after understanding the underlying theory. A circular buffer is a data structure where the array is processed and visualized in the form of loops, that is, indexes return to 0 after reaching the length of the array. This is done using two pointers to the array: “head” and “tail”. When data is added to the buffer, the header pointer moves up. Similarly, when they are removed, the tail also moves up. The definition of the head, tail, direction of their movement, the place of writing and reading depends on the implementation of the scheme.
Circular buffers are overly used to solve consumer problems. That is, one thread of execution is responsible for the production of data, and the other for consumption. In embedded devices with a very low and medium level, the manufacturer is presented in the ISR format (information received from sensors), and the consumer is presented in the form of a main event cycle.
A feature of cyclic buffers is that they are implemented without the need for locks in the environment of one manufacturer and one consumer. This makes them an ideal information structure for embedded programs. The next difference is that there is no exact way to differentiate a filled sector from an empty one. This is because in both cases the head merges with the tail. There are many ways and workarounds to deal with this, but most of them add a lot of confusion and make reading difficult.
Another issue that arises regarding a circular buffer. Do I need to flush new data or overwrite existing data when it is full? Experts argue that there is no clear advantage of one over the other, and its implementation depends on the specific situation. If the latter are of more relevance to the application, use the rewrite method. On the other hand, if they are processed in the "first come - first served" mode, then discard new ones when the ring buffer is full.
Loop queue implementation
Getting started, define data types, and then methods: core, push and pop. In the push and pop procedures, the “next” offset points are calculated for the location at which the current write and read will occur. If the next location points to the tail, then the buffer is full and data is no longer being written. Similarly, when “head” is equal to “tail”, it is empty and nothing is read from it.
Standard use case
The helper procedure is called by the application process to retrieve data from the Java ring buffer. It should be included in critical sections if more than one stream is being read from a container. The tail moves to the next offset before the information is read, since each block is one byte and the same amount is reserved in the buffer when the volume is fully loaded. But in more advanced cyclic storage implementations, single partitions need not be the same size. In such cases, they try to save even the last byte, adding more checks and boundaries.
In such schemes, if the tail moves before reading, the information to be read can potentially be overwritten by the newly pushed data. In general, it is recommended that you read and then move the tail pointer first. First, determine the length of the buffer, and then create an instance of "circ_bbuf_t" and designate the pointer "maxlen". In this case, the container must be global or be on the stack. So, for example, if you need a 32-byte ring buffer, do the following in the application (see the figure below).
Functional Requirement Specification
The data type “ring_t” will be a data type that contains a pointer to a buffer, its size, header and tail index, data counter.
The initialization function “ring_init ()” initializes the buffer based on the receipt of a pointer to the container structure created by the calling function, which has a predefined size.
The ring_add () call add function will add a byte to the next available space in the buffer.
The delete ring_remove () function will remove the byte from the oldest valid location in the container.
The ring peek in the ring_peek () function will read the number of bytes of “uint8_t 'count'” from the ring buffer into the new buffer provided as a parameter, without deleting any values read from the container. It will return the number of bytes actually read.
The ring clearing function “ring_clear ()” will set “Tail” to “Head” and load “0” in all positions of the buffer.
Creating a buffer in C / C ++
Due to the limited resources of embedded systems, data structures with a circular buffer can be found in most fixed-size projects that work as if the memory was continuous and cyclic in nature. Data does not need to be rearranged, as memory is generated and used, and head / tail pointers are adjusted. When creating a circular buffer library, users need to work with the library APIs rather than changing the structure directly. Therefore, encapsulation of the ring buffer on C is used. Thus, the developer will save the library implementation, changing it as necessary, without requiring end users to update it as well.
Users cannot work with the "circular_but_t" pointer; a handle type is created that can be used instead. This eliminates the need to provide a pointer in the implementation of the ".typedefcbuf_handle_t" function. Developers need to build an API for the library. They interact with the “C” ring buffer library using the opaque descriptor type that is created during initialization. Usually, uint8_t is chosen as the base data type. But you can use any particular type, being careful to properly handle the base buffer and the number of bytes. Users interact with the container, performing the required procedures:
- Initialize the container and its size.
- Dump the circular container.
- Add data to the ring buffer on "C".
- Get the next value from the container.
- Request information on the current number of elements and maximum capacity.
Both "full" and "empty" cases look the same: "head" and "tail", pointers are equal. There are two approaches that distinguish between full and empty:
- Full state tail + 1 == head.
- Empty state head == tail.
Library function implementation
To create a circular container, use its state management structure. To preserve encapsulation, the structure is defined inside the library “.c” file, and not in the header. During installation, you will need to track:
- Base data buffer.
- The maximum size.
- The current position of the head, increasing with the addition.
- The current tail, increasing when removed.
- A flag indicating whether the container is full or not.
Now that the container is designed, library functions are implemented. Each of the APIs requires an initialized buffer descriptor. Instead of clogging the code with conditional statements, apply statements to enforce the style requirements of the API.
An implementation will not be thread-oriented unless locks have been added to the core circular storage library. To initialize the container, the API has clients that provide the base buffer size, therefore they create it on the library side, for example, for the sake of malloc simplicity. Systems that cannot use dynamic memory must change the “init” function to use a different method, such as allocating containers from a static pool.
Another approach is to break encapsulation, which allows users to statically declare container structures. In this case, circular_buf_init needs to be updated to take a pointer or init, create a stack structure and return it. However, since encapsulation is broken, users will be able to change it without library procedures. After the container is created, fill in the values and call "reset". Before returning from init, the system ensures that the container is created in an empty state.
Adding and deleting data
Adding and removing data from the buffer requires manipulation of the “head” and “tail” pointers. When added to the container, a new value is inserted in the current "head" place and promoted. When removed, get the value of the current tail pointer and advance tail. If you need to promote the tail indicator, as well as the head, you need to check whether the insert causes the value "full". When the buffer is already full, push the tail one step ahead of the head.
After the pointer has been advanced, fill in the "full" flag, checking the equality of "head == tail". Modular use of the operator will cause the "head" and "tail" to reset to "0" when the maximum size is reached. This ensures that “head” and “tail” will always be valid indices of the underlying data container: “static void advance_pointer (cbuf_handle_t cbuf)”. You can create a similar helper function that is called when a value is removed from the buffer.
Template Class Interface
In order for the C ++ implementation to support any data types, the template is executed:
- Flush buffer to clear.
- Adding and deleting data.
- Check full / empty state.
- Check the current number of items.
- Checking the total capacity of the container.
- To avoid leaving any data after the destruction of the buffer, C ++ smart pointers are used to ensure that users can manage the data.
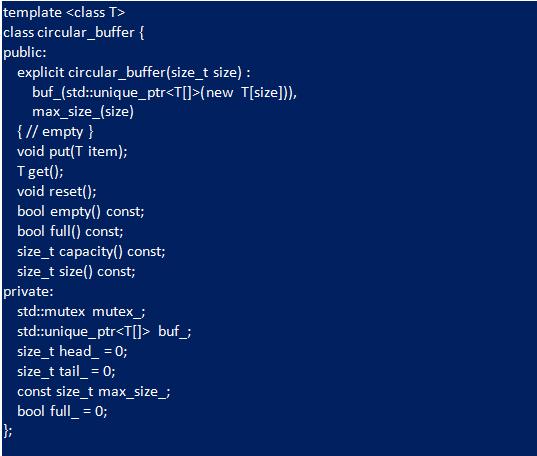
In this example, the C ++ buffer mimics much of the C implementation logic, but the result is a much cleaner and reusable design. In addition, the C ++ container uses "std :: mutex" to provide a thread-oriented implementation. When creating a class, data is allocated for the main buffer and its size is set. This eliminates the overhead required with the implementation of C. In contrast, the C ++ constructor does not call "reset" because it indicates the initial values for the member variables, the circular container starts in the correct state. The reset behavior returns the buffer to an empty state. In a C ++ circular container implementation, "size" and "capacity" reports the number of elements in the queue, not the size in bytes.
UART STM32 Driver
After starting the buffer, it should be integrated into the UART driver. First, as a global element in the file, so you need to declare:
- "descriptor_rbd" and buffer memory "_rbmem: static rbd_t _rbd";
- "static char _rbmem [8]".
Since this is a UART driver, where each character must be 8-bit, creating an array of characters is acceptable. If 9- or 10-bit mode is used, then each element must be "uint16_t". The container is calculated in such a way as to avoid data loss.
Often, queue modules contain statistical information that allows you to track maximum usage. In the initialization function “uart_init”, the buffer must be initialized by calling “ring_buffer_init” and passing the attribute structure with each member to which the discussed values are assigned. If it is successfully initialized, the UART module is reset, receiving interruption is enabled in IFG2.
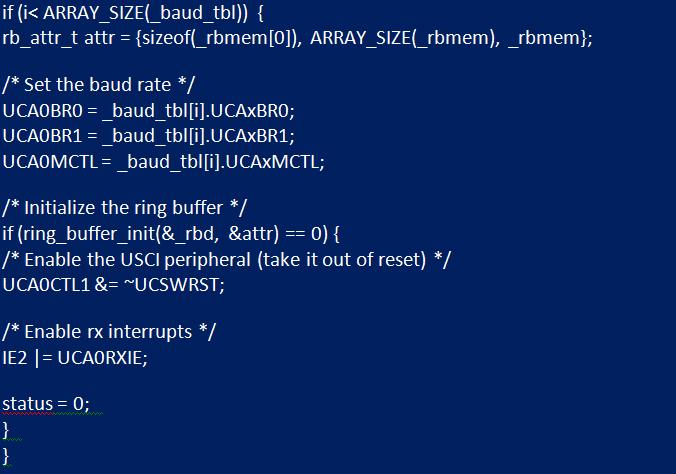
The second function that needs to be changed is uart_getchar. Reading the received character from the UART peripheral is replaced by reading from the queue. If the queue is empty, the function should return -1. Next, you need to implement UART to get ISR. Open the header file "msp430g2553.h", scroll down to the interrupt vector section, where a vector with the name USCIAB0RX is found. Naming implies that it is used by USCI modules A0 and B0. USCI A0 interrupt status can be read from IFG2. If it is set, the flag must be cleared, and the data in the receiving compartment is buffered using "ring_buffer_put".
UART Data Repository
This repository provides information on how to read UART data using DMA when the number of bytes to receive is not known in advance. In the family of microcontrollers, the STM32 ring buffer can operate in different modes:
- Polling mode (without DMA, without IRQ) - the application should poll status bits to check if a new character has been received, and read it fast enough to receive all bytes. A very simple implementation, but no one uses it in real life. Cons - it is easy to skip the received characters in data packets, it works only for low bit rates.
- Interrupt mode (without DMA) - the UART ring buffer triggers an interrupt, and the CPU switches to a utility program to process data reception. The most common approach in all applications today, works well in the medium speed range. Cons - the interrupt processing procedure is performed for each character received, it can stop other tasks in high-performance microcontrollers with a large number of interrupts and at the same time the operating system when receiving a data packet.
- DMA mode is used to transfer data from the USART RX register to user memory at the hardware level. At this stage, interaction with the application is not required, except for the need to process the data received by the application. It can be very easy to work with operating systems. Optimized for high data rates> 1Mbps and low-power applications, in the case of large data packets, increasing the buffer size can improve functionality.
Implementation in ARDUINO
The Arduino ring buffer refers both to the design of boards and to the programming environment that is used for work. The core of the Arduino is the Atmel AVR series microcontroller. It is the AVR that does most of the work, and in many ways, the Arduino board around the AVR represents functionality - easy-to-connect contacts, a USB-serial interface for programming and communication.
Many of the usual Arduino boards currently use the ATmega 328 ring buffer, while older boards used the ATmega168 and ATmega8. Boards like Mega choose more sophisticated options, such as 1280 and similar. The faster Due and Zero, the better use ARM. There are about a dozen different Arduino boards with names. They can have different amounts of flash memory, RAM, and I / O ports with an AVR ring buffer.
The variable "roundBufferIndex" is used to store the current position, and when added to the buffer, the array will be limited.
These are the results of code execution. Numbers are stored in the buffer, and when they are full, they begin to be overwritten. Thus, you can get the last N numbers.
The previous example used an index to access the current position of the buffer, because it is sufficient to explain the operation. But in general, it is normal that a pointer is used. This is modified code to use a pointer instead of an index. In fact, the operation is the same as the previous one, and the results are similar.
High Performance CAS Operations
Disruptor is a high-performance cross-thread messaging library developed and opened several years ago by LMAX Exchange. They created this software to handle huge traffic (over 6 million TPS) in their retail financial trading platform. In 2010, they surprised everyone with how fast their system can be, performing all the business logic in a single thread. Although one thread was an important concept in their solution, Disruptor operates in a multi-threaded environment and is based on a ring buffer - a stream in which obsolete data is no longer needed because it is more recent and more relevant.
In this case, either a false boolean return or a lock will work.If none of these solutions satisfies users, you can implement a buffer with a variable size, but only when it is full, and not only when the manufacturer reaches the end of the array. Resizing will require moving all the elements to a newly allocated larger array if it is used as the basic data structure, which, of course, is an expensive operation. There are many other things that make Disruptor fast, such as consuming batch messages.
The qtserialport ring buffer (serial port) is inherited from the QIODevice, can be used to receive various serial information and includes all of the available serial devices. The serial port is always open for exclusive access, which means that other processes or threads cannot access the open serial port.
Ring buffers are very useful in C programming, for example, you can evaluate the stream of bytes arriving through UART.